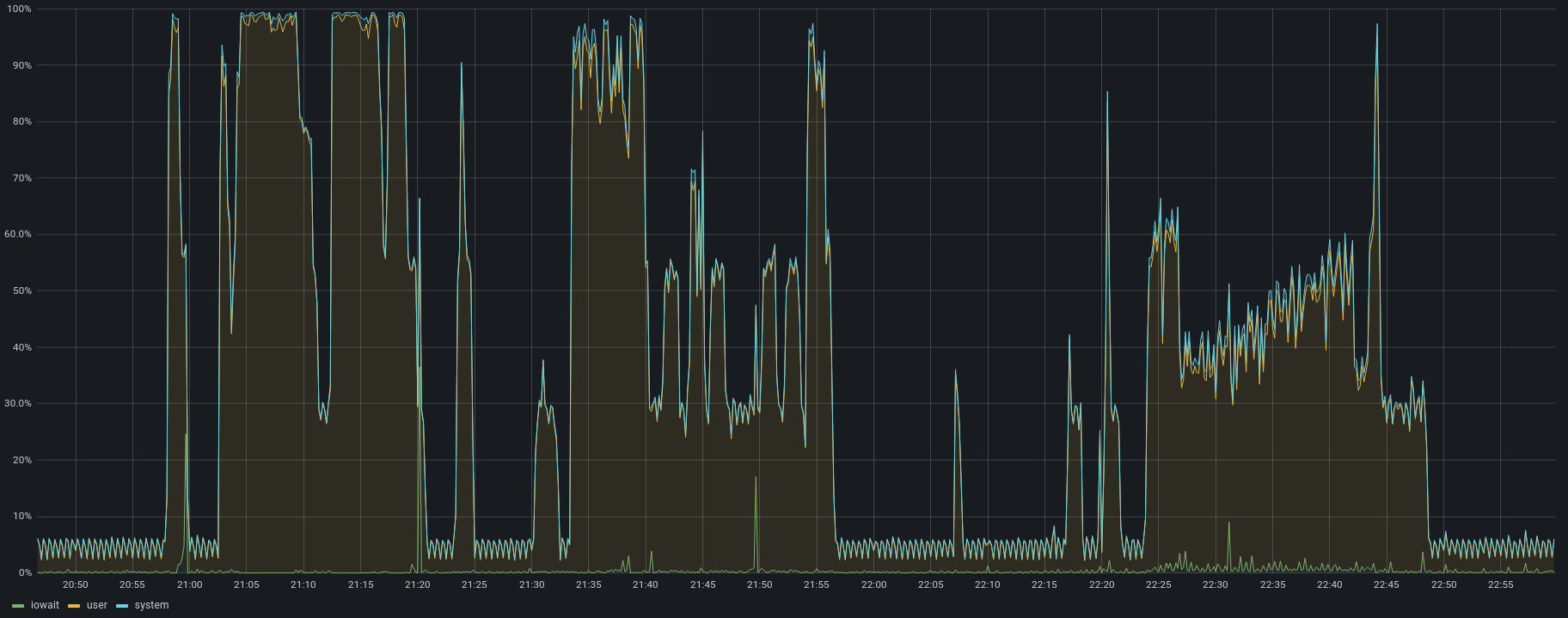
This is where the story becomes less fun. So I start Nexus, grabbed some water, and it was still starting. Looking at the logs it didn’t seem to do much, but the CPU was pegged. So surely it’s still progressing. Now let’s be clear, I run my PIs pretty funky. Most of my data storage is on an NFS server, and I haven’t seen the best performance with it. Not sure whether I’m just missing some configuration tweaks or if I just expected too much from RAID 10 with spinning rust. Nonetheless, I was quite stunned that it took almost an hour to start Nexus. Clearly, something was up here, but whatever. If it’s just the start-up, I can live with it.
Sadly, this is not where the sad tales stopped. My connection was only 60 mbit/s, so the bar to beat wasn’t all that high. I took my local Maven settings, configured Nexus as the Maven Central mirror, cleared my cache, and tried to compile one of projects. CPU went up, downloads were very slow, but it worked. Most importantly, on the second try it was faster than pulling it from the internet again. Still, why did Nexus spike to 100% CPU on user time. I expected my NFS setup to be the bottleneck here, not the PI CPU.
One issue with Nexus is that it’s quite an old project using a modular runtime, which tends to mean upgrading beyond JRE 8 is a major hassle. Java 9’s major change was the (in)famous Project Jigsaw. Strong isolation of Java Modules, disallowing access to internal modules by default, sprinkled with the moving of a few Java EE specs out of the JDK and into their own artifacts. This is not why I care about running Nexus on a newer JRE though. Both Java 9 and Java 11 had a few improvements for AARCH64/ARMv8, so potentially this better platform integration could improve performance.
Of to google it is! Let’s see if Nexus supports deploying on Java 11. No. The answer is No: NEXUS-19183 (It finally seems to gain some traction though). But I’m a guy who likes suffering and doing stupid things. There were comments in the JVM configuration telling me to enable a few flags to adjust some Java 9 Module settings. So, why wouldn’t it work?
A word of warning here, this is all me tinkering with the Nexus deployment. This is in no way a supported or endorsed way of running Nexus. I’m a very light user and don’t really keep important data in there. If you want to mimic this, be sure to not store data you care about in the deployment. With that out of the way, let’s start tinkering.
Boy did they trick me good. So I think these comments are just some defaults from whatever packaging plugins they use. As their start-up script specifically checks that you’re running JRE 8, and nothing newer. I can change a bash script though, so off to the races it was. Note: I wrote this post a “while” after I actually did this, at the time Nexus 3.37.0-01 was current. Let’s modify the start-up script to allow Java 11+ as well.
--- nexus 2021-11-20 00:40:48.000000000 +0700
+++ nexus 2022-04-07 22:05:53.324782442 +0700
@@ -158,7 +158,9 @@
return;
fi
if [ "$ver_major" -gt "1" ]; then
- return;
+ if [ "$ver_major" -lt "11" ]; then
+ return;
+ fi
elif [ "$ver_major" -eq "1" ]; then
if [ "$ver_minor" -gt "8" ]; then
return;
I had a bunch of issues with the script’s very clever JRE lookup. So I ended up uninstalling JRE 8 while trying to get Nexus to pick up JRE 11.
Let’s also uncomment all those --add-reads, --add-opens, --add-exports and --patch-module (expect for org.apache.karaf.specs.locator-4.3.2.jar, I’ll come back to that one).
This is where they wasted another good amount of my time.
The sharp-eyed may have noticed that some flags have an = and some don’t.
Even for the same flags.
Which doesn’t work.
Funnily the error Unrecognized option: --patch-module sounds like I’m running on JRE 8 still.
But I removed it.
There’s only a JRE 11 available.
After pulling my hair out and reading the JEPs around Jigsaw, I realized that all of them need to have an = to work… Thanks.
With JVM creation errors out of the way, I could see what errors cropped up during startup.
After a few iterations of starting and looking at the module path errors, I ended up adding the following lines:
--add-exports=java.base/org.apache.karaf.specs.locator=java.xml,ALL-UNNAMED
--add-exports=java.base/javax.activation=java.datatransfer,ALL-UNNAMED
--add-reads=java.base=java.datatransfer
--add-opens=java.base/java.security=ALL-UNNAMED
As instructed we’ll also need to comment out the endorsed dirs.
The endorsed lib mechanism is no longer through a folder with random JARs that override the JDK.
With the module path we’re expected to use --patch-module to specifically alter a module.
After a bit of toying around, I found that the default patch for java.base seems incomplete.
The classes from locator seem to need activation classes.
Now, this is a bit of a pickle as we can only apply a single patch per module.
Luckily the jar format is a fairly simple format: It’s just a zip file with “stored” files (ie, no compression).
The only issue might be if we have duplicate files in the META-INF folders between the 2 jars that we want to merge.
So, let’s try it and see what happens.
pushd lib/endorsed/
mkdir ultra-patch
cp org.apache.karaf.specs.locator-4.3.2.jar ultra-patch/
cp ../boot/activation-1.1.jar ultra-patch/
pushd ultra-patch/
unzip -n org.apache.karaf.specs.locator-4.3.2.jar
unzip -n activation-1.1.jar
zip -0 -r base-patch.jar * -x org.apache.karaf.specs.locator-4.3.2.jar -x activation-1.1.jar
popd
popd
Now that we got a jar that could maybe patch our java.base, let’s configure it:
--patch-module=java.base=lib/endorsed/ultra-patch/base-patch.jar
And with that, I got a functioning Nexus running on JRE 11. The results are quite stunning though. Startup time? 2 minutes… A “minor” improvement here. Downloading artifacts? Much faster too. Let’s compare.
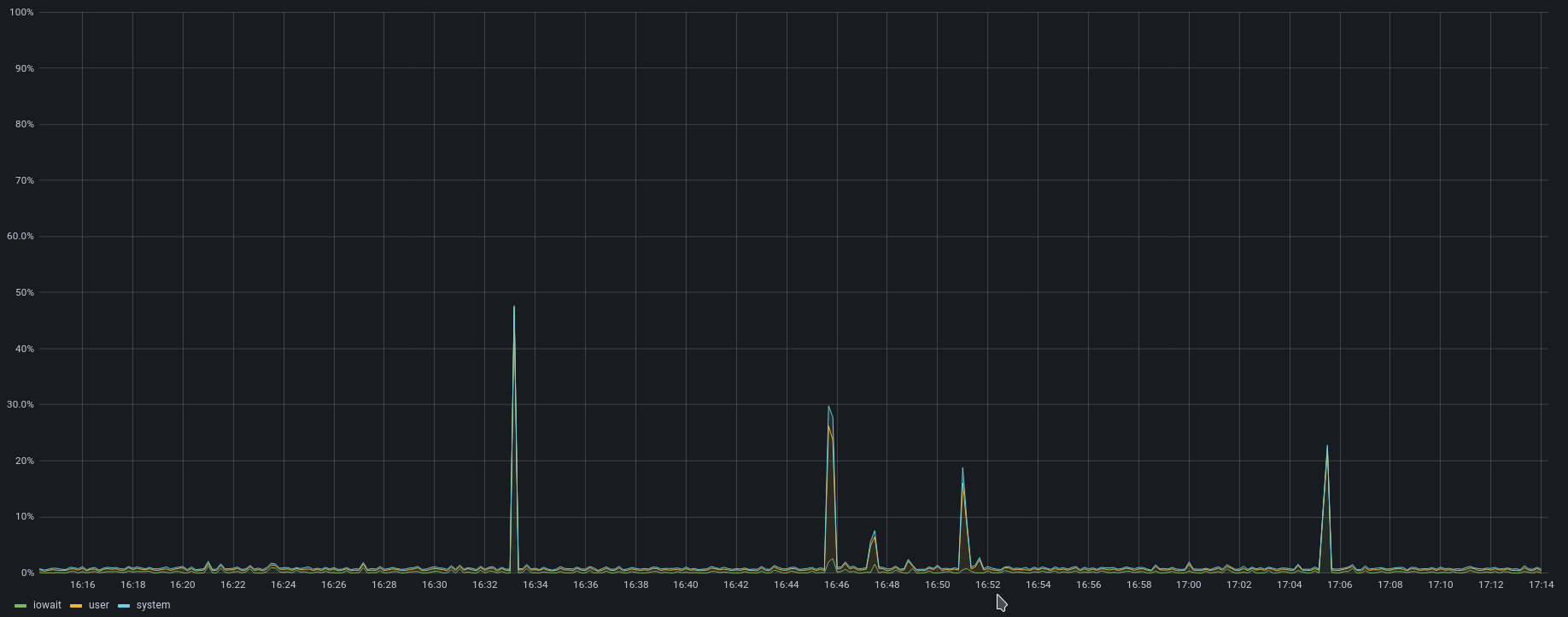
Overall a very good result. But as this is all quite hacky it’s kinda a barrier to upgrade to newer versions. Will it still work? Probably but downgrading Nexus isn’t supported, so it’s a nice way to get into a broken state. If you’re running Nexus on a Raspberry PI, I can highly recommend trying this as well though. Night and day difference in performance. Even the web UI is a lot more responsive.
]]>